Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 안드로이드 스튜디오
- 자바스크립트
- 백준
- css기초
- JS프로그래머스
- 알고리즘
- JS
- 익스프레스
- dp알고리즘
- 백준골드
- CSS
- 백준구현문제
- 몽고DB
- js코테
- 리액트댓글기능
- 다이나믹프로그래밍
- HTML5
- HTML
- 백준nodejs
- 프로그래머스
- 백준구현
- 코테
- 코딩테스트
- 리액트커뮤니티
- 프로그래머스코테
- 리액트
- 프로그래머스JS
- 포이마웹
- 백준알고리즘
- 백준js
Archives
- Today
- Total
개발새발 로그
이분탐색 본문
저장되어있는 데이터를 탐색하는 방법은 크게 두가지로 나뉩니다.
바로 순차탐색과 이분탐색입니다.
먼저 순차탐색에 대해 알아 보겠습니다.
순차탐색
5 9 2 1 4 3 8 0 7 에서 데이터 2는 몇번째 위치에 존재할까요??
0부터0까지의 숫자 중 2를 찾아야하는데 숫자들 서로 연관없이 무작위로 섞여있습니다.
이럴때는 단순하게 앞에서부터 하나씩 데이터를 확인하여 탐색해야합니다.
순차탐색은 데이터의 정렬유무에 상관없이 앞에서부터 데이터를 하나씩 확인하여 탐색하는 알고리즘입니다.
이분탐색
1 3 5 7 9 11 13 15 17 19 21 23에서 데이터 11은어디에 존재하는가?
여기에서는 이미 배열의 데이터가 정렬되어있는 상태입니다.
이런 상황에서는 데이터를 더 빠르게 탐색할 수 있습니다.
이유는 다른 위치에 있는 데이터의 범위를 추측할 수 있기 때문입니다.
예를 들어 9의 오른쪽의 숫자들은 9보다 항상 큽니다.
이분탐색은 맨 처음에 중간 위치에서부터 출발한다는 특징이있습니다.
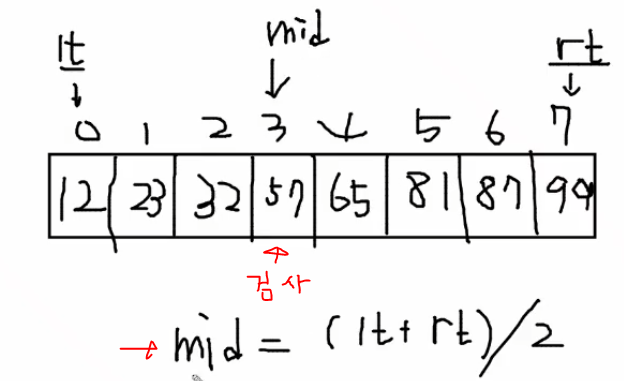
위와 같이 mid 값을 검사하고 만약 찾는 값이 아니면 lt와 rt중에 하나를 mid값으로 바꿉니다.
이유는 그 이후나 이전을 탐색할 필요가 없기 때문입니다.
그리고 mid값은 lt와 rt값의 2를 나눈 값으로 바꾸면 됩니다,
이를 반복하면 lt와rt가 같아지거나 찾는 값이 mid가 되는 상황이 우리가 정답을 찾게되는 것입니다.
이분탐색은 한 번 탐색할 때마다 크기를 반으로 줄여나간다는 점에서 시간 복잡도 O(Log2N)의 시간 복잡도를 가집니다.
728x90
반응형
LIST
'알고리즘' 카테고리의 다른 글
| Dynamic Programming(냅색 알고리즘-1) (0) | 2023.06.07 |
|---|---|
| Dynamic Programming -(최대 부분 증가 수열[LIS]) (0) | 2023.06.07 |
| 그리디 알고리즘 기초문제 풀이 (3) | 2023.06.04 |
| 그리디 알고리즘 (0) | 2023.06.04 |
| 에라토스테네스의 체 (0) | 2023.06.04 |
'알고리즘' Related Articles
more



